Why Your AI Agent Is Flying Blind (And What to Do About It)
The Illusion of Capability
When you watch a demo of a modern AI agent, it looks impressive. It answers questions, takes actions, reasons through problems. It seems to understand you and the world around you.
Then you try to use it for something real and it falls apart.
"I don't have access to your calendar." "I can't see that file." "I don't have real-time information about that."
The model is capable. The agent is blind.
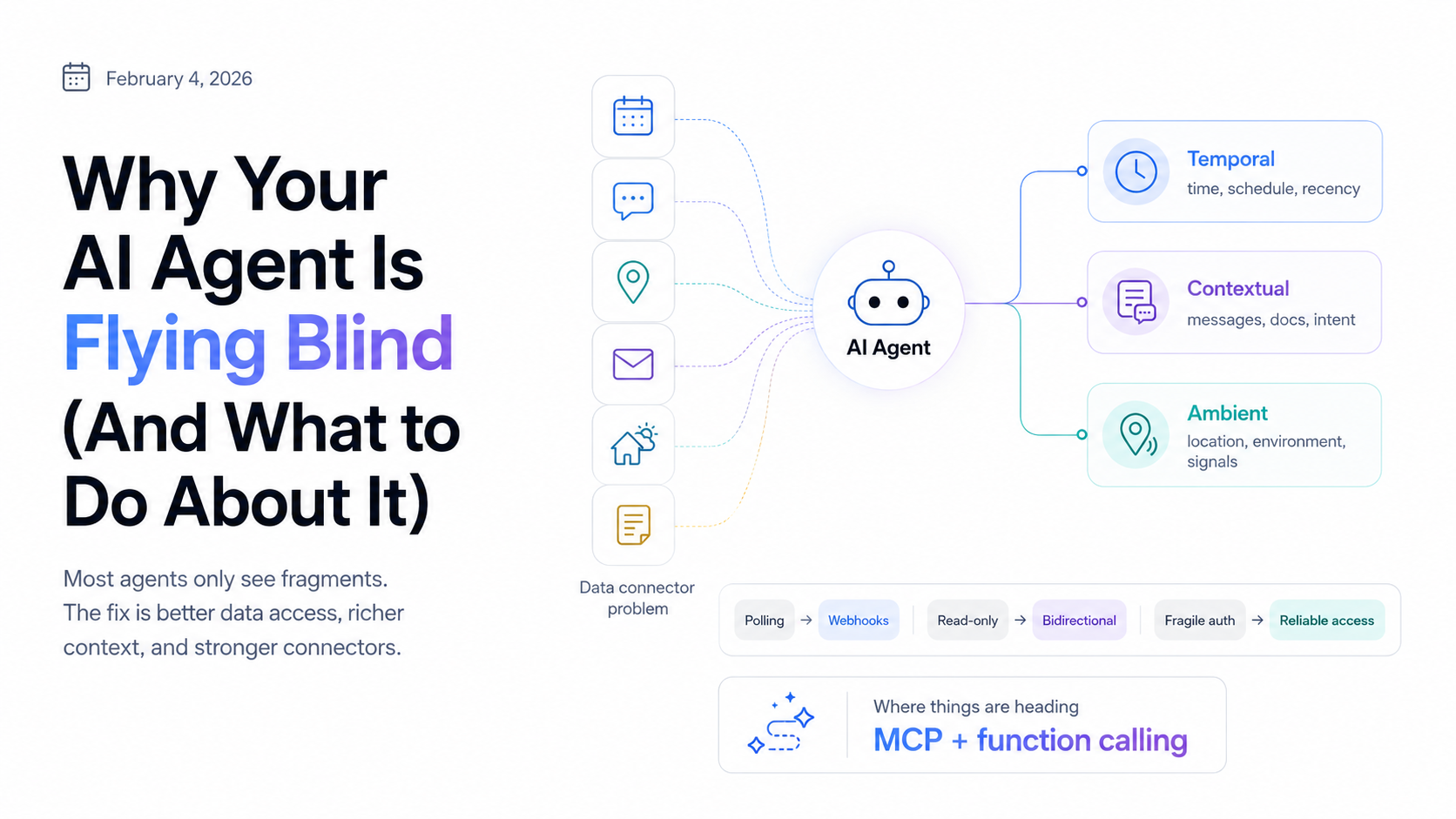
This is the data connector problem, and it's the most underrated bottleneck in applied AI right now. We have remarkably good models. We have increasingly sophisticated agent frameworks. What we don't have, in most cases, is clean, reliable access to the data that would actually make those agents useful.
A thoughtful agent with incomplete data is just a confident guesser. The connectors aren't a nice-to-have. They're what separate useful from impressive-looking.
What Data Connectors Actually Are
Before I go further: when I say "data connector," I don't mean a dashboard integration or a reporting feed. I mean a live, bidirectional interface between an AI agent and a data source that lets the agent:
- Query the data source with specific questions
- Interpret the response in context
- Write back when an action should update the source of record
The third part is where most implementations stop. They'll read from your calendar but won't create events. They'll pull task data but won't update it. They'll ingest documents but won't draft anything back to the system it came from.
A read-only connector makes your agent informed. A read-write connector makes your agent actually useful.
The Avery Data Problem
When I started building Avery, I made the classic mistake: I assumed integration was the easy part.
I spent six months on the AI core—the conversation model, the memory system, the proactive messaging logic. All the interesting stuff. Then I turned to integrations and realized I'd underestimated the problem by roughly an order of magnitude.
Google Calendar turned out to be the first real lesson. The API is well-documented. OAuth is well-understood. But making calendar data actually useful to an agent is a different thing entirely.
Reading events is straightforward. The hard part is:
- Interpreting what the events mean (is a "sync" a quick check-in or a heavy meeting requiring prep?)
- Understanding patterns across events (Taylor's Tuesday mornings are usually meeting-heavy, so don't suggest deep work then)
- Managing token refresh across sessions without auth failures surfacing in user conversations
- Reconciling calendar state with task state when they conflict
Every connector has this pattern. The API is the easy part. The interpretation layer—turning raw data into something an agent can reason with—is where the real engineering lives.
The Taxonomy of Data a Personal Agent Needs
After a year of building Avery, I've started thinking about agent data in three layers:
Temporal data — What's happening when? Calendar events, deadlines, recurring commitments, time-zone-aware scheduling. This data is fast-moving and high-consequence. Being wrong about what's on your calendar isn't a minor UX issue. It breaks trust.
Contextual data — What's your life like right now? Tasks, goals, ongoing projects, preferences, relationships. This is slower-moving but deeply personal. The agent needs to hold a coherent model of this that evolves over time without becoming stale.
Ambient data — What's happening in the world that's relevant to you? Weather, traffic, news about your industry, availability of services you use. This is real-time and ephemeral. Today's weather is irrelevant by tomorrow.
Most agent implementations handle one of these reasonably well and neglect the others. Avery started strong on contextual data (because that's the core of a personal AI assistant) and had to deliberately build out temporal and ambient data over time.
What surprised me: the interactions between these layers are where the value is. Knowing you have a big meeting tomorrow (temporal) + knowing you tend to get anxious before high-stakes presentations (contextual) + knowing there's a weather event that might affect your commute (ambient) = an agent that proactively reaches out the evening before with exactly the right kind of support. Separately, each layer is useful. Together, they're powerful.
Why Most Integrations Feel Shallow
I've used a lot of AI tools that claim to integrate with my workflow. Almost all of them feel shallow. Here's why.
Problem 1: Polling instead of webhooks. Most integrations sync on a schedule—every hour, every 15 minutes. That means the data is always stale. An agent that checks your email every hour isn't useful for time-sensitive things. Real-time responsiveness requires event-driven architecture: webhooks that push changes to the agent as they happen.
Problem 2: Flat data models. APIs return structured data. Agents need to understand relationships. Your calendar event for "Team standup" is related to the task "Prepare standup notes" which is related to your goal "Improve team communication." A connector that treats each piece of data in isolation loses all of that context.
Problem 3: No write-back. An agent that reads your tasks but can't update them creates a split record. You're maintaining two systems: the app and the AI's view of the app. Eventually they diverge and you stop trusting the agent. Bidirectional sync isn't a nice-to-have. It's table stakes for an agent that's supposed to actually manage things.
Problem 4: Auth fragility. OAuth tokens expire. Refresh tokens can be revoked. API rate limits exist. Most integrations handle the happy path and fail opaquely when something goes wrong. Users see "I couldn't access your calendar" with no explanation and no path to fix it. Good connector architecture means graceful degradation and clear recovery flows, not silent failures.
What Solving This Actually Looks Like
The right mental model for data connectors in an agent context is: each connector is an adapter that translates between the native language of the data source and the native language of the agent.
The data source speaks in its own schema—Google Calendar events have summary, start, end, attendees. The agent needs to understand "you have a two-hour meeting tomorrow morning with three people, one of whom you haven't talked to in six months." The connector does that translation.
This means every connector needs:
- A schema mapping that translates raw API responses into agent-readable concepts
- A relevance filter that decides what to surface and what to suppress (not every calendar event matters to every conversation)
- A freshness layer that knows when data is current vs. stale
- An action interface that maps agent intents to API mutations
Building this well for one data source takes real time. Building it for many requires a framework—some common layer that each connector plugs into rather than reinventing the wheel.
We're still building that framework for Avery. What exists today works, but it's brittle in places. The next big engineering investment is making connectors first-class: well-tested, independently deployable, and composable so the agent can reason across multiple sources simultaneously without the integration complexity leaking into the conversation logic.
Where the Industry Is Heading
The Anthropic tool use API, OpenAI's function calling, the MCP (Model Context Protocol) spec—these are all attempts at standardizing how agents interact with external data and systems. They're a good sign. They mean the industry is starting to take the connector problem seriously.
But standards are a starting point. The hard work is in the implementations. And the most valuable thing any agent can offer, near-term, is reliable, real-time, bidirectional access to the data that actually runs people's lives.
Calendar. Tasks. Email. Documents. Communication platforms. Health data. Financial data. These aren't exotic integrations. They're the core of how most knowledge workers spend their days.
An agent that can see all of this, reason across it, and take action within it—that's not a productivity tool. That's a genuine cognitive extension. A second brain that's always on, always up to date, and always working with the full picture.
Most agents today are working with a fragment of that picture. The ones that figure out the data layer first will pull ahead. Fast.
I'm building Avery to be one of them.
See these ideas in practice
Avery is the proactive AI assistant built on everything written here. It lives on WhatsApp and reaches out to you—not the other way around.
Get started with Google