The Memory Problem No One Is Talking About
What Memory Actually Means for an AI Agent
There's a moment every Avery user hits within the first few days. They tell her something important—a deadline, a preference, a personal goal—and then a few days later she references it at exactly the right moment. Not because she was programmed to. Because she remembered.
That sounds simple. It is not simple.
Building memory into an AI agent is one of the genuinely hard problems in applied AI right now, and it's underappreciated because most people conflate "memory" with "storage." Those are completely different things. Storing data is trivial. Knowing what to store, how to retrieve it, and when to surface it is the actual challenge.
Most AI tools have perfect recall of your last conversation and zero recall of anything else. That's not memory. That's a chat log.
The Conversation Window Trap
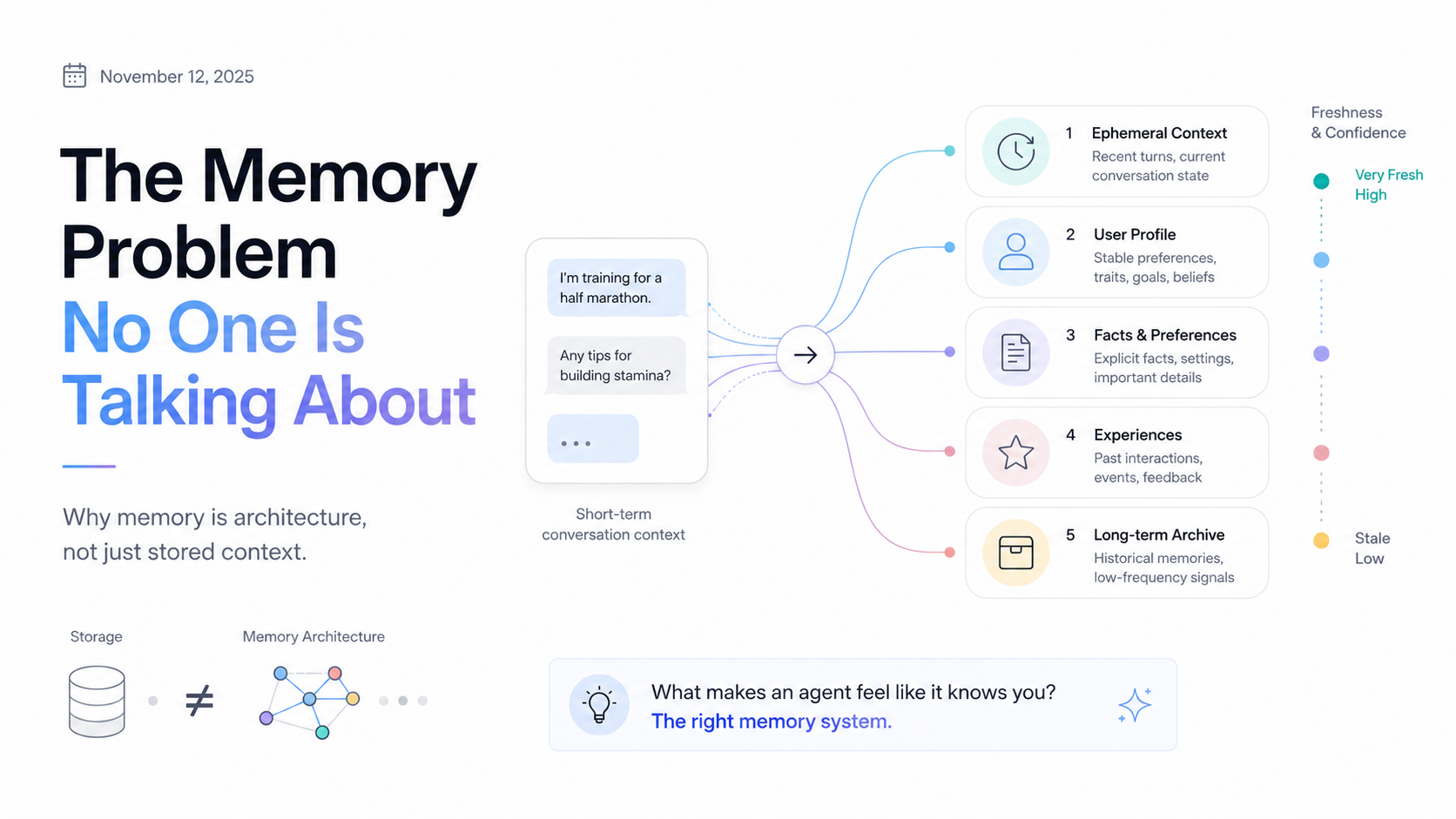
Every large language model operates with a context window—a finite amount of text it can "see" at once. The naive approach to memory is just to keep adding to that window: stuff every previous conversation in there and hope the model figures out what matters.
This breaks quickly.
Context windows have token limits. Shove too much in and either you hit a hard cap or the model starts losing coherence at the edges. And even before those limits, there's a subtler problem: signal-to-noise ratio. If you've been using Avery for six months, your raw conversation history is enormous—and 90% of it is noise. Routine check-ins, confirmations, small talk. The 10% that actually matters gets diluted.
We tried this approach early on. The results were underwhelming. The model would "remember" that you mentioned loving Thai food but miss that you'd said you were trying to cut back on takeout this month. Recent, specific constraints got buried under older, less relevant data.
Memory as a First-Class Architecture Decision
The breakthrough was treating memory as its own system rather than a feature bolted onto conversations.
Instead of feeding raw history to the model, we now run a separate extraction pass after each conversation. The model asks itself: What facts about this person are worth preserving? What changed since the last time we talked? The output is a set of structured memory objects—not sentences, not chat logs, but discrete facts with metadata: when the fact was learned, how confident we are it's still true, and what category it belongs to.
The categories that matter most:
- Preferences — How you like to work, when you have energy, what kinds of tasks you batch together
- Commitments — Things you've said you'll do that haven't been marked done yet
- Goals — Longer-horizon intentions that don't map to a single task
- Context — Facts about your life that shape how advice should be framed (kids, job, health things)
- Patterns — Behavioral tendencies we've inferred from repeated behavior
Each category has a different decay profile. Preferences are relatively stable. Commitments need to be checked and cleared regularly or they become noise. Context facts can become stale in ways that matter a lot—someone's job situation changes, their family structure changes, and an agent operating on old context becomes not just unhelpful but actively tone-deaf.
The Staleness Problem
Here's something that almost never gets talked about: stale memory is worse than no memory.
If Avery remembers you were job hunting six months ago and keeps surfacing that context, it's annoying at best and unsettling at worst. An assistant who brings up old information that no longer applies feels invasive rather than helpful. It signals that the system is running on a rigid model of you rather than actually understanding you.
We built an explicit confidence decay model into our memory system. Facts age. High-confidence facts from six months ago become medium-confidence facts. Things that haven't been confirmed recently start getting flagged for verification rather than silently assumed.
This creates some interesting design challenges. You don't want to pepper users with "hey, is this still true?" questions constantly—that's annoying and breaks the conversational flow. But you also need to refresh your model of them. Our solution was to make verification feel natural: when a memory is relevant to something we're helping with, we'll use the interaction to implicitly validate it. If you mention something that contradicts an old memory, we update without drawing attention to it.
The goal isn't an AI that remembers everything you've ever said. It's an AI that holds a coherent, current model of you—and knows when to let old facts go.
Retrieval Is Half the Battle
Storing memories well is only half the problem. Knowing which memories to pull into context for any given conversation is equally hard.
The naive approach is semantic search: embed all your memories, embed the user's message, find the closest matches. This works for some cases but fails for others. "What should I work on today?" is a vague query that doesn't map cleanly to any specific memory—but it needs to draw on your current task list, your energy patterns, your calendar, and your broader goals simultaneously.
We ended up with a layered retrieval approach:
-
Always-on context: A small set of high-relevance facts that get included in every conversation. Current goals, active commitments, key preferences. This is like working memory—the stuff that should always be available.
-
Triggered retrieval: Pattern-matched retrieval that fires based on what the current conversation is about. Discussing exercise? Pull fitness-related memories. Planning an event? Pull social preferences and scheduling patterns.
-
Temporal retrieval: What's time-sensitive right now? Upcoming deadlines, recent commitments, things scheduled for this week.
The hard part is that these three layers can conflict. Something in the always-on layer might be superseded by something in triggered retrieval. A recent commitment might contradict an older pattern. The model has to reconcile these on the fly, and sometimes it gets it wrong.
What Actually Makes an Agent Feel Like It Knows You
I've been paying attention to when users say Avery feels "like she actually gets me"—because that's the goal and it's surprisingly hard to characterize.
It's not about how much the agent remembers. It's about the quality of inference the agent makes from what it knows. A user who mentioned in passing that they were training for a marathon doesn't need to be reminded about that marathon every day. But when they're trying to schedule a long meeting on a weekend morning, Avery flagging that they typically have long runs then is exactly the right use of that memory.
The agent needs to know when memory is load-bearing for a decision, and only surface it then.
This is a much harder problem than retrieval. It requires the model to understand the decision being made, identify which facts are relevant to it, and weigh them appropriately—all in a single turn with no explicit instruction to do so. We're getting better at it, but this is genuinely frontier work. The infrastructure exists. The judgment is what's still being calibrated.
Where This Is Heading
The next frontier isn't bigger context windows. It's better memory architecture.
There's a reason the most useful humans in your life—a great assistant, a good therapist, a close friend—feel useful in proportion to how well they know you. Not because they remember more facts, but because they've built an accurate, nuanced model of how you think and what you need. They use that model to anticipate rather than just react.
That's what we're building toward with Avery. Not a more powerful chatbot. An agent that has a genuine, maintained, evolving model of each person it works with—and uses that model to make every interaction feel exactly right.
Memory isn't a feature. It's the foundation.
See these ideas in practice
Avery is the proactive AI assistant built on everything written here. It lives on WhatsApp and reaches out to you—not the other way around.
Get started with Google